爬虫抓取数据

首先:爬虫常用的模块有requests和BeautifulSoup和lxml,所以要先用pip安装对应的模块,注意BeautifulSoup已被移到bs4。
Pip install lxml
Pip install bs4
BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间。可以参考两个网址:
英文:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
中文:https://beautifulsoup.readthedocs.io/zh_CN/latest/
其次:要玩爬虫,还要懂一些html,因为要分析dom结构。
下面的例子将从新闻中获取两个东西,一个是热点新闻,一个是热搜新闻词,跟着我来:
1, 用浏览器打开新闻网址
2, 按F12查看dom结构,发现热点要闻都是在一个<strong>的标记里。
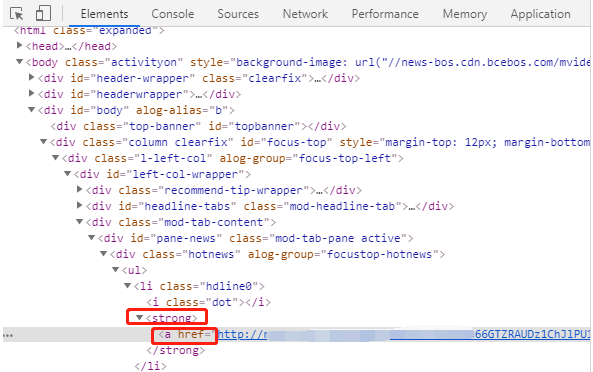
3, 尝试一下看行不行
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
# headers是模拟浏览器
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.1) Gecko/20090624 Firefox/3.5",
"Accept": "text/plain", 'Connection': 'close'}
url = "http://news.xxx.com/"
# requests.get将返回URL的html内容
r = requests.get(url, headers=headers)
# 将返回的hmtl内容交给BeautifulSoup去格式化
soup = BeautifulSoup(r.text, 'html.parser')
# 获取热点新闻
# 获取所有strong标记
for s in soup.find_all('strong'):
time.sleep(3)
# 获取strong标记下的a标记
a = s.find_all('a')
# 获取a标记中的文本
title = a[0].string
# 获取a标记中的链接发址
href = a[0].get('href')
print('%s%s%s' % (title, ' : ', href))
这里用到time.sleep(3),是每隔3秒获取一条新闻,虽然有headers模拟浏览器,但程序总是很快的,这样会引起服务器的察觉,你不是一个浏览器,是一个爬虫程序,可能会被屏蔽。相当于我们用程序模拟人工浏览网页的时间。点一条新闻看3秒,再去点开另一个条新闻。另外headers中加入'Connection': 'close' 有助于提高不会被发现是爬虫的机率,好多现有爬虫文章都没有用到这个。
运行以上程序看看结果,发现可以获取到热点新闻:
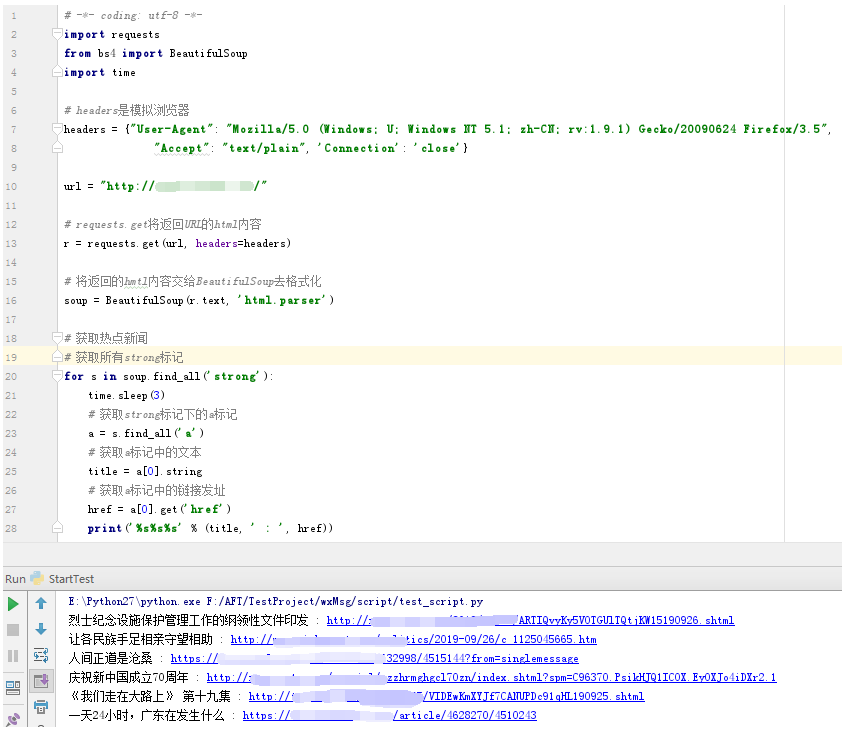
4,接着继续看热搜新闻词的dom结构
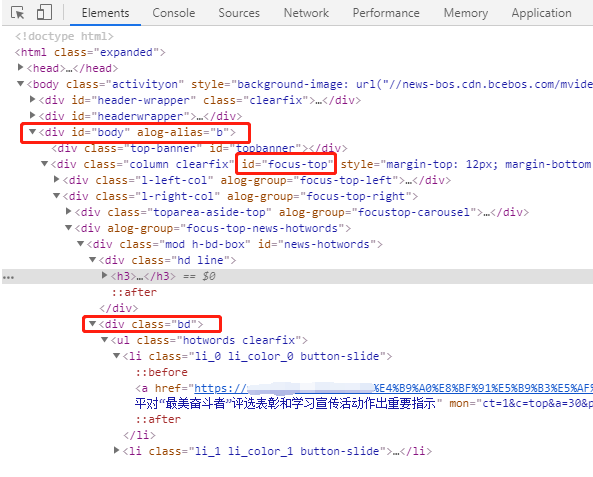
这次试着按dom 结构的层次往下找:
在<body>下面有一个DIV,它的ID是body,
再往下一层,有个DIV,它的ID是focus-top,
再往下一层,有个DIV,它的class是 l-right-col,
再往下一层,有个DIV,它的class是bd
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
# headers是模拟浏览器
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.1) Gecko/20090624 Firefox/3.5",
"Accept": "text/plain", 'Connection': 'close'}
url = "http://news.xxxx.com/"
# requests.get将返回URL的html内容
r = requests.get(url, headers=headers)
# 将返回的hmtl内容交给BeautifulSoup去格式化
soup = BeautifulSoup(r.text, 'html.parser')
# 获取热搜新闻词
body = soup.body
# 获取 id 为 body 的 div层
div_1 = body.find('div', {'id': 'body'})
# 获取 id 为 focus-top 的 div层
div_2 = div_1.find('div', {'id': 'focus-top'})
# 获取 class 为 l-right-col 的 div层
div_3 = div_2.find('div', class_='l-right-col')
# 获取 class 为 bd 的 div层
div_4 = div_3.find('div', class_='bd')
# 在class 为 bd 的 div层里获取所有a链接
hotwords = div_4.find_all('a',target="_blank")
for h in hotwords:
time.sleep(3)
print '%s%s%s' % (h.text, ' : ', h.get('href'))
因为class是关键字,所以用class_ 。运行结果如下:
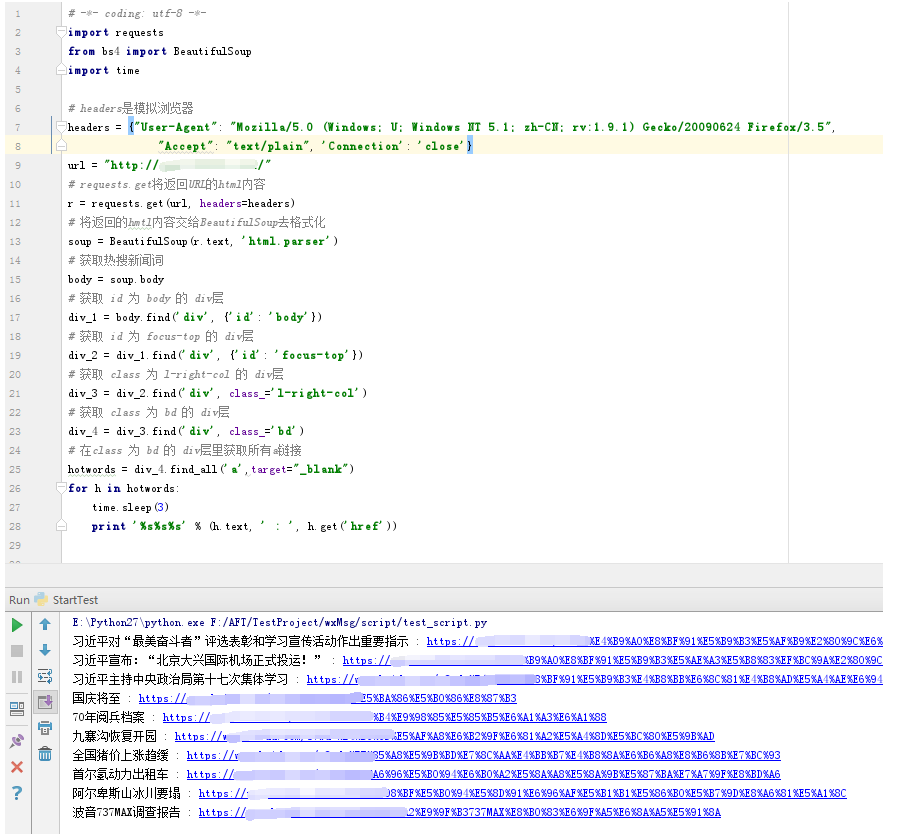
把这两个程序合并一起,完整的如下:
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
# headers是模拟浏览器
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.1) Gecko/20090624 Firefox/3.5",
"Accept": "text/plain", 'Connection': 'close'}
url = "http://news.xxx.com/"
# requests.get将返回URL的html内容
r = requests.get(url, headers=headers)
# 将返回的hmtl内容交给BeautifulSoup去格式化
soup = BeautifulSoup(r.text, 'html.parser')
# 获取热点新闻
# 获取所有strong标记
for s in soup.find_all('strong'):
time.sleep(3)
# 获取strong标记下的a标记
a = s.find_all('a')
# 获取a标记中的文本
title = a[0].string
# 获取a标记中的链接发址
href = a[0].get('href')
print('%s%s%s' % (title, ' : ', href))
# 获取热搜新闻词
body = soup.body
# 获取 id 为 body 的 div层
div_1 = body.find('div', {'id': 'body'})
# 获取 id 为 focus-top 的 div层
div_2 = div_1.find('div', {'id': 'focus-top'})
# 获取 class 为 l-right-col 的 div层
div_3 = div_2.find('div', class_='l-right-col')
# 获取 class 为 bd 的 div层
div_4 = div_3.find('div', class_='bd')
# 在class 为 bd 的 div层里获取所有a链接
hotwords = div_4.find_all('a',target="_blank")
for h in hotwords:
time.sleep(3)
print '%s%s%s' % (h.text, ' : ', h.get('href'))
第一个超简单的爬虫就做完了,这里只是简单的将结果打印出来,至于结果数据要如何处理就看各位需要了。
声明:仅供学习参考
该文章对你有帮助吗,求分享转发: 分享到QQ空间 分享给QQ好友