爬虫抓取图片

上一节介绍的是获取文字,这一节介绍获取图片并下载到本地。
用urllib模块很方便从网页上下载东西。
1, 在浏览器打开 http://www.xxxx.com/xxx/shuiguotupian/ ,按F12查看dom结构:发现图片是放在一个class为list-pic的DIV里,而且img里的src有完整的图片地址。
2, 开始尝试写:
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
import urllib
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.1) Gecko/20090624 Firefox/3.5",
"Accept": "text/plain", 'Connection': 'close'}
url = 'http://www.xxx.com/xxx/shuiguotupian/'
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
div1 = soup.find('div', class_='list-pic')
imgs = div1.find_all('img')
for img in imgs:
time.sleep(3)
print '%s%s' % ('正在下载图片:',img['src'])
img_name = img['src'].split('/')[-1]
try:
urllib.urlretrieve(img['src'], "%s%s" % ('D:\\img\\', img_name))
except:
continue
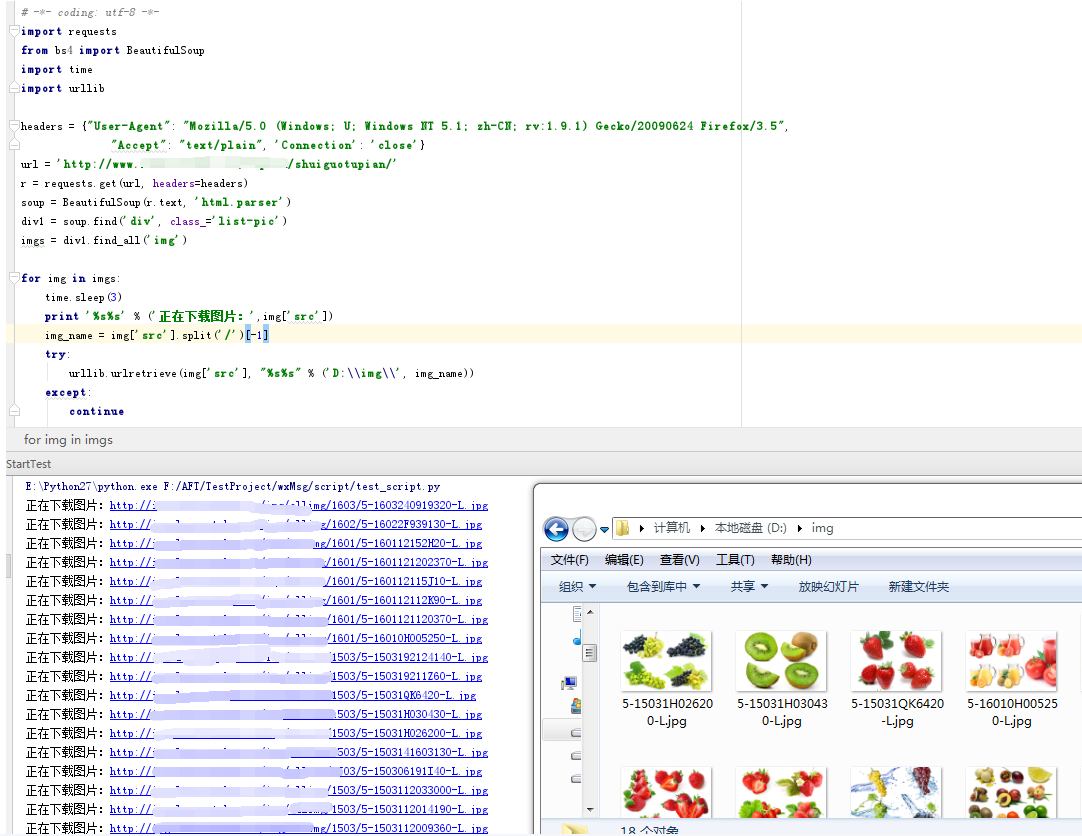
发现是可以正常下载图片的:
声明:仅供学习参考
该文章对你有帮助吗,求分享转发: 分享到QQ空间 分享给QQ好友